
Het probleem van een ‘domme’ AI die jouw bedrijf niet kent
Herken je dit scenario? Je opent je favoriete AI-tool om snel een offerte op te stellen op basis van een klantgesprek van vorige week. Maar in plaats van een bruikbaar document krijg je een generiek tekstje dat nergens op slaat. De AI weet namelijk niets van jouw specifieke prijzen, jouw eerdere afspraken of de unieke werkwijze van je bedrijf. Het voelt als werken met een briljante stagair die de hele wereldencyclopedie uit zijn hoofd kent, maar nog nooit één voet in je kantoor heeft gezet. Dit gebrek aan context is frustrerend en zorgt ervoor dat de technologie vaak meer tijd kost dan het oplevert.
Het gevolg is dat je kostbare tijd verliest aan het micromanagen van de technologie in plaats van het benutten ervan. Je bent continu bezig met het handmatig kopiëren en plakken van stukjes tekst, e-mails en PDF-inhoud in de chat, in de hoop dat de AI het snapt. Bedrijven noemen dit gebrek aan context en de onmogelijkheid om veilig bij eigen data te komen vaak als de grootste struikelblokken bij AI-adoptie in 2026 (Gartner). In plaats van automatisering creëer je eigenlijk een nieuw soort administratief proces dat net zo traag is als het oude. Bovendien brengt het risico’s met zich mee als medewerkers gevoelige data in openbare modellen plakken zonder na te denken over privacy.
Gelukkig is er een oplossing die de kracht van grote taalmodellen koppelt aan de specifieke kennis van jouw organisatie: Retrieval-Augmented Generation, of kortweg RAG. Zie RAG als de ideale brug tussen jouw interne documentatie en de intelligentie van AI. Voordat het systeem antwoord geeft, zoekt het eerst in jouw eigen “archiefkast” naar de juiste informatie om het antwoord te onderbouwen. Het is het verschil tussen een vreemde om de weg vragen en iemand die een kaart van jouw specifieke locatie in handen heeft. Op deze manier krijg je antwoorden die niet alleen vlot geschreven zijn, maar ook feitelijk kloppen met jouw bedrijfsrealiteit.
Wat is een RAG-systeem? (Retrieval-Augmented Generation) simpel uitgelegd
Veel mensen denken ten onrechte dat RAG een compleet nieuw en complex AI-model is dat je moet trainen. Het is eigenlijk een slimme werkmethode die jouw bestaande AI-model, zoals GPT-4, toegang geeft tot jouw unieke bedrijfsinformatie. Een handige vergelijking om dit te begrijpen is het verschil tussen een examen maken uit je hoofd en een ‘open boek’ examen doen. Een standaard AI-model moet gokken op basis van algemene internetkennis die het jaren geleden heeft geleerd. Een RAG-systeem mag daarentegen letterlijk spieken in jouw documentatie, handleidingen en e-mails voordat het antwoord geeft. Hierdoor verandert de AI van een betweterige buitenstaander in een goed geïnformeerde collega die jouw specifieke werkwijze kent.

Het technische proces achter deze methode is verrassend logisch en bestaat in de kern uit drie heldere stappen. Wanneer jij of je medewerker een vraag stelt, duikt het systeem eerst razendsnel in jouw eigen gekoppelde kennisbank om relevante passages te vinden (Retrieve). Vervolgens combineert de software deze specifieke bedrijfsinformatie met jouw oorspronkelijke vraag in een instructie voor het taalmodel. Pas in de laatste stap schrijft de AI een antwoord (Generate), waarbij het verplicht is om de gevonden informatie als bron te gebruiken. Dit proces dwingt de technologie om eerst de feiten te checken in jouw archief voordat het een verhaal begint te genereren. Je krijgt dus geen creatief verzinsel, maar een feitelijk antwoord dat is verpakt in vlot leesbare taal.
Deze aanpak pakt direct het grootste obstakel aan voor zakelijk AI-gebruik in 2026: de betrouwbaarheid van de output. Omdat het model strikt gebonden is aan jouw bronmateriaal, neemt de kans op zogenaamde hallucinaties of verzonnen feiten drastisch af. Onderzoek toont zelfs aan dat RAG-systemen het aantal feitelijke fouten met wel 60 tot 80% kunnen verminderen in vergelijking met standaard chatbots. Dit betekent dat je de output daadwerkelijk kunt vertrouwen voor klantcommunicatie of interne besluitvorming zonder dat je elke zin panisch hoeft te controleren. Voor organisaties die veiligheid en correctheid belangrijk vinden, is dit simpelweg de enige verantwoorde manier om LLM’s (Large Language Models) in te zetten.
Hoe een RAG-systeem in de praktijk werkt: een helder stappenplan
Het technische proces achter een RAG-systeem lijkt op het eerste gezicht misschien ingewikkeld, maar het volgt eigenlijk een heel logisch stappenplan. In plaats van een ondoorzichtige ‘black box’ waar je maar op moet vertrouwen, is het een transparante keten van acties die we heel nauwkeurig kunnen afstellen. Vaak denken ondernemers dat ze hun hele hebben en houden moeten uploaden naar een openbaar model, maar dat is een misvatting die we graag uit de wereld helpen. Je houdt namelijk volledige controle over welke data wel of niet beschikbaar is voor de AI. Laten we eens kijken hoe dit proces in de praktijk verloopt, verdeeld over drie heldere fases die zich binnen enkele seconden voltrekken.
Stap 1: De kennisbank bouwen (Vector Database)
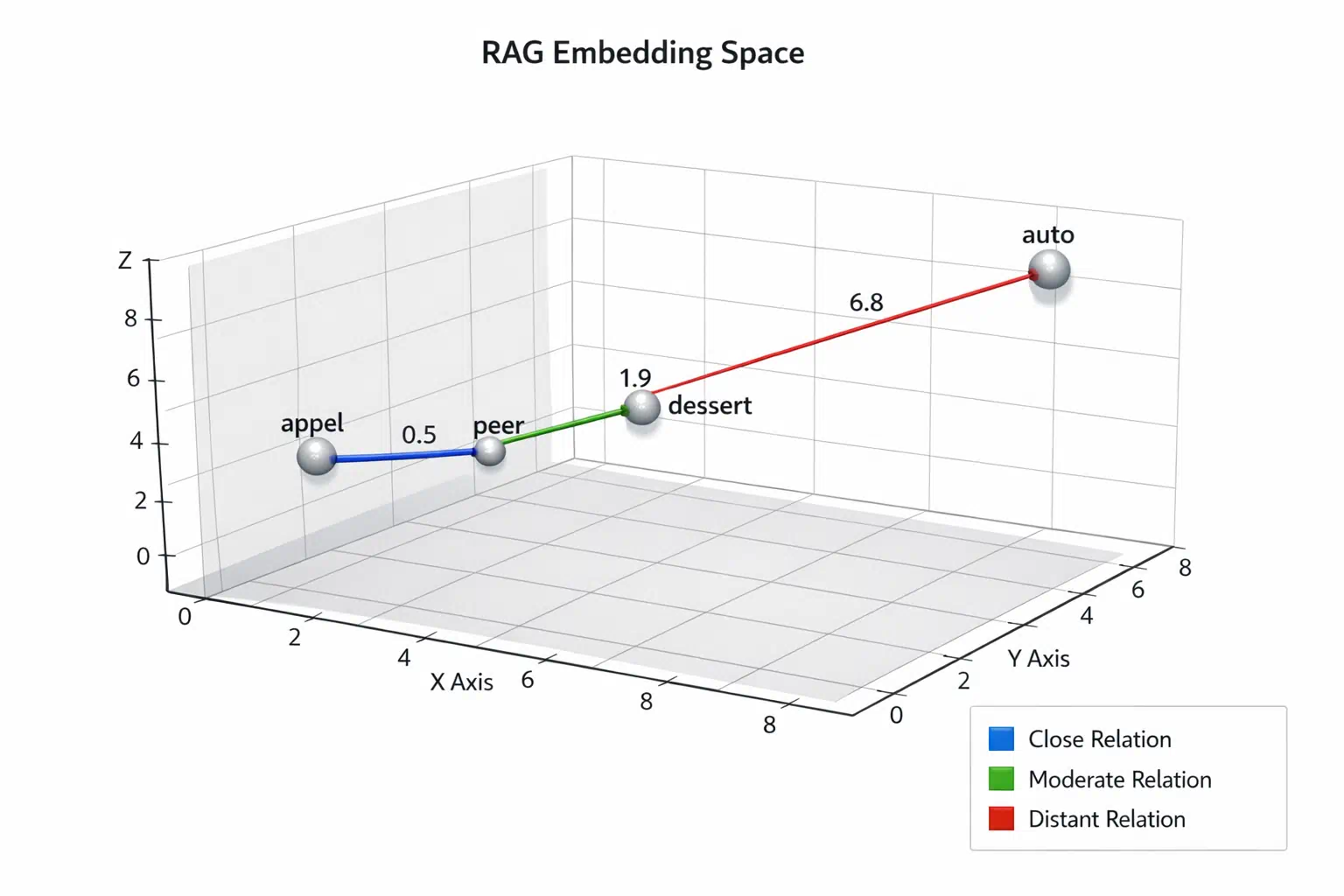
Alles begint met het toegankelijk maken van je eigen bedrijfsinformatie in een formaat dat de computer razendsnel kan lezen. We nemen hierbij jouw bestaande documenten zoals PDF-bestanden, Word-documenten of pagina’s uit Confluence en delen deze op in kleine, logische tekstblokjes. Deze fragmenten worden vervolgens omgezet naar complexe reeksen getallen, wat we in de technische wandelgangen ‘embeddings‘ of vector-data noemen. Embeddings zijn gewoon cijfercodes zoals “0.0013008557” of “0.057021752”. Het bijzondere aan deze techniek is dat concepten met een vergelijkbare betekenis wiskundig dicht bij elkaar komen te staan in de database . De cijfercode voor appel ligt met andere woorden vrij dicht bij die van peer. Neem je de code voor dessert dan ligt die al wat verderaf, maar niet zo veraf als de code voor auto, want dat heeft met fruit of eten al helemaal niets te maken. Dit indexeren is trouwens meestal een eenmalige klus die we daarna simpelweg automatisch laten bijwerken via tools als n8n. In onze dagelijkse praktijk merken we dat de kwaliteit van deze ‘tekstblokjes’ staat of valt met een goede voorbewerking van de brondocumenten; rommelige opmaak zorgt voor rommelige output.
Stap 2: De vraag en het zoekproces (Retrieval)
Wanneer jij of een collega vervolgens een vraag stelt aan de chatbot, gebeurt er iets interessants op de achtergrond. Het systeem stuurt je vraag niet direct door naar de AI, maar gebruikt deze eerst als zoekopdracht in jouw eigen vector-database. Omdat we met die slimme nummercodes werken, begrijpt de software de context en intentie achter je woorden veel beter dan een simpele zoekbalk -ik verwijs graag naar Pinecone voor meer info ter zake. Typ je bijvoorbeeld ‘facturatieprobleem grote klant’, dan vindt het systeem direct de relevante procedures en eerdere mailwisselingen, zelfs als die exacte woorden er niet letterlijk in staan. Het resultaat is dat de software de drie of vier meest relevante stukjes informatie opvist die nodig zijn voor een goed antwoord. Je krijgt dus geen duizenden zoekresultaten, maar een gecureerde selectie van feiten die er op dat moment echt toe doen.
Stap 3: Het antwoord genereren (Augmented Generation)
Pas in deze laatste fase komt het grote taalmodel daadwerkelijk in beeld om de puntjes op de i te zetten. We sturen jouw oorspronkelijke vraag, samen met de zojuist gevonden informatiepakketjes, als één bundel naar de AI. Hierbij geven we een hele specifieke instructie mee: beantwoord de vraag van de gebruiker, maar gebruik hiervoor alleen de feiten die we je net hebben gegeven. Deze methode dwingt de technologie om zich te gedragen als een nauwkeurige analist in plaats van een creatieve schrijver die maar wat verzint. Het model gebruikt zijn taalkundige kracht om een vloeiend lopend antwoord te schrijven, terwijl de inhoud strikt gebaseerd blijft op jouw bedrijfsdata. Zo krijg je het beste van twee werelden; een vlot leesbaar verhaal dat ook nog eens feitelijk klopt met hoe jij werkt.
Expert Tip: Begin klein bij het bouwen van uw eerste vector database. We zien te vaak dat bedrijven al hun documenten tegelijk willen indexeren, wat snel leidt tot verwarring en vervuiling van de resultaten. Vanuit onze ervaring is het veel effectiever om te starten met één duidelijke bron, zoals de handleidingen van de klantenservice, en dit eerst goed werkend te krijgen voordat u opschaalt.
Het cruciale verschil: standaard LLM vs. RAG-systeem
Het fundamentele verschil tussen een standaard taalmodel en een RAG-systeem zit hem in de herkomst en versheid van hun kennis. Een publieke versie van tools zoals ChatGPT vertrouwt volledig op informatie die het tijdens zijn training heeft geleerd, wat betekent dat de kennis vaak maanden of zelfs jaren oud is. Het model weet misschien alles over de wereldgeschiedenis, maar het heeft logischerwijs geen toegang tot de prijswijziging die je gisteren in je interne systeem hebt doorgevoerd. Een RAG-systeem doorbreekt deze beperking door jouw actuele, beveiligde bedrijfsdata als de primaire bron van waarheid te gebruiken. Hierdoor verandert de AI van een algemene encyclopedie in een gespecialiseerde adviseur die precies weet wat er nu speelt binnen jouw organisatie. Dit maakt het systeem bruikbaar voor serieuze taken in plaats van alleen voor creatieve tekstproductie.
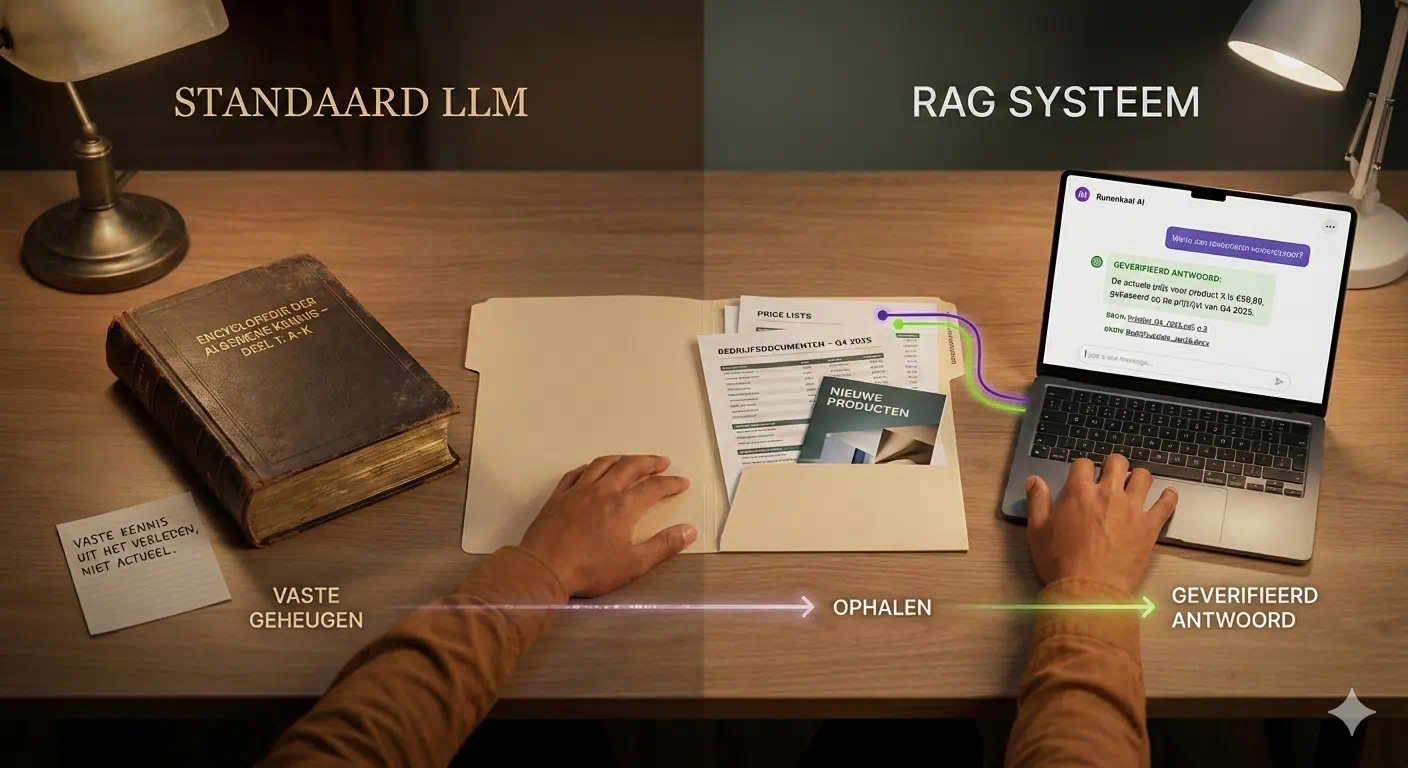
Daarnaast zien we een enorme verbetering in de controleerbaarheid van de output wanneer we deze methode toepassen in een zakelijke context. Bij een standaard model is de AI vaak een ‘black box’ die een antwoord geeft zonder dat je weet waar het vandaan komt, wat leidt tot onzekerheid over de juistheid. Een RAG-systeem lost dit op door niet alleen het antwoord te geven, maar ook direct de bronnen te tonen die het heeft gebruikt voor dat specifieke antwoord. Dit mechanisme zorgt voor transparantie; je kunt direct doorklikken naar de originele PDF of e-mail om de context te verifiëren. Volgens experts is deze verifieerbaarheid de sleutel tot succesvolle adoptie van AI binnen kritische bedrijfsprocessen. Dit bouwt het noodzakelijke vertrouwen op om automatisering veilig in je team te integreren.
Tot slot is de flexibiliteit van het systeem een doorslaggevende factor voor bedrijven die in een snel veranderende markt opereren. Een standaard AI-model volledig opnieuw trainen om nieuwe kennis toe te voegen is een proces dat weken duurt en tienduizenden euro’s kost. Bij een RAG-opstelling is dit probleem compleet verdwenen; zodra jij een nieuw bestand in je database zet, is die kennis direct beschikbaar voor de chatbot. Dit betekent dat je handleidingen, prijslijsten of beleidsstukken kunt wijzigen zonder dat je de hele technische infrastructuur hoeft aan te passen. Wanneer wij systemen inrichten via flexibele workflows, merken we dat deze wendbaarheid klanten enorm geruststelt omdat ze nooit ‘vast’ zitten aan verouderde modellen. Voor organisaties die wendbaar willen blijven, is dit dynamische karakter essentieel om efficiënt te blijven werken. Het maakt AI niet langer een statisch archief, maar een levend systeem dat elke dag met je bedrijf meegroeit.
De voordelen van RAG voor jouw bedrijf: meer dan alleen een slimme chatbot
We kennen allemaal de frustratie van het eindeloos spitten in digitale mappen op zoek naar dat ene specifieke beleidsdocument of die oude offerte. Deze inefficiëntie is een enorme productiviteitskiller; uit recent onderzoek van McKinsey blijkt dat kenniswerkers nog steeds bijna twee uur per dag kwijt zijn aan het zoeken naar informatie. Dat is kostbare tijd die verloren gaat aan administratie in plaats van aan waardevol werk. Door een RAG-systeem te implementeren, win je die tijd effectief terug omdat de antwoorden direct beschikbaar zijn in je chat-omgeving. Bedrijven die deze stap in 2025 hebben gezet, rapporteren vaak een vermindering van 40 tot 60 procent in zoektijd. Het verandert een zoektocht van twintig minuten in een simpele vraag van tien seconden.

Snelheid is prettig, maar consistentie is wat een bedrijf echt helpt om succesvol te schalen zonder kwaliteitsverlies. Een grote uitdaging voor groeiende teams is ervoor zorgen dat een junior supportmedewerker hetzelfde hoogwaardige antwoord geeft als een senior accountmanager met tien jaar ervaring. Een RAG-systeem fungeert als een centrale bron van waarheid die de communicatie over alle afdelingen heen standaardiseert. Dit heeft vooral impact op nieuwe medewerkers: cijfers laten zien dat de inwerktijd met de helft kan worden verkort wanneer starters direct toegang hebben tot een intelligente kennisban. In plaats van collega’s te storen met repetitieve vragen, kunnen ze het systeem raadplegen voor accurate en goedgekeurde antwoorden vanaf hun eerste werkdag.
Voor veel organisaties komt de terughoudendheid om AI te omarmen voort uit terechte zorgen over databeveiliging en de nauwkeurigheid van de output. Het gebruik van een RAG-architectuur pakt dit probleem bij de wortel aan door jouw gevoelige data binnen je eigen gecontroleerde omgeving te houden, in plaats van een publiek model ermee te trainen. Deze aanpak verhoogt daarnaast de betrouwbaarheid enorm; omdat de AI gedwongen wordt om bronnen te citeren, daalt het risico op “hallucinaties” of verzonnen feiten met wel 80 procent. Bij Bonalogic zien we deze controle als essentieel voor een professionele werkwijze. Het transformeert AI van onvoorspelbaar speelgoed naar een deterministische zakelijke tool die je daadwerkelijk kunt vertrouwen voor communicatie met klanten.
Inzicht uit de Praktijk: Snelheid is belangrijk, maar in onze implementatietrajecten merken we dat traceerbaarheid uiteindelijk van grotere waarde is. Het feit dat een leidinggevende kan zien welk document exact is gebruikt voor een antwoord, biedt een mate van juridische en operationele controle die bij standaard chatbots volledig ontbreekt.
Praktische use cases waar je vandaag al mee kan starten
Veel ondernemers denken bij AI nog steeds aan futuristische toekomstmuziek, maar de realiteit in 2026 is veel praktischer en direct toepasbaar. We zien bij Bonalogic dagelijks dat juist de relatief eenvoudige toepassingen vaak de meeste impact maken op de dagelijkse gang van zaken. Het gaat hierbij niet om het vervangen van mensen, maar om het wegnemen van die saaie zoektaken die niemand leuk vindt en die veel tijd kosten. De technologie is inmiddels zo toegankelijk geworden dat je echt geen multinational hoeft te zijn om je eigen data slim in te zetten voor je team. Laten we eens kijken naar drie concrete scenario’s die we vandaag de dag vaak bouwen voor onze klanten en die direct rendement opleveren.
De meest voor de hand liggende toepassing is wat wij in de wandelgangen vaak de Interne Kennisbank 2.0 noemen. In plaats van dat medewerkers verdwalen in mappenstructuren op SharePoint of Google Drive om een specifieke procedure te vinden, stellen ze gewoon een vraag in de chat. Het systeem zoekt direct in de personeelshandboeken, IT-handleidingen of beleidsstukken en geeft binnen enkele seconden het juiste, bondige antwoord. Dit scheelt niet alleen de zoeker tijd; het voorkomt ook dat de HR-manager voor de tiende keer dezelfde vraag over verlofdagen of declaraties moet beantwoorden via de mail. Wij hebben gezien dat HR-afdelingen hierdoor tot wel 30% minder repetitieve tickets binnenkrijgen in de eerste maand na livegang. Volgens experts op het gebied van digitale adoptie is dit vaak het ideale startpunt voor het MKB omdat de winst in tijd en frustratie direct voelbaar is.
Voor marketingteams en contentmakers biedt een RAG-opstelling een krachtige oplossing voor het probleem van dertien-in-een-dozijn teksten. Je kunt het systeem namelijk voeden met al je eerdere whitepapers, succesvolle blogs en interne stijlgidsen om de unieke stem van je merk te leren kennen. Wanneer je vervolgens vraagt om een opzetje voor een nieuwe nieuwsbrief of LinkedIn-post, gebruikt de AI jouw eigen archief als stijlgids en bronmateriaal voor de content. Dit zorgt ervoor dat de output klinkt alsof het door jouw eigen team is geschreven in plaats van door een generieke robot die je bedrijf niet snapt. Marketingbureaus die deze techniek toepassen, merken dat ze veel sneller kunnen produceren zonder in te leveren op de kwaliteit of de authenticiteit van hun boodschap.
Ook in commerciële en technische rollen zien we dat de razendsnelle toegang tot historische data goud waard is voor de efficiëntie van het team. Een supportmedewerker hoeft bij een complexe storing niet meer door vijf verschillende technische handleidingen te bladeren, want de assistent vat de oplossing direct samen uit de documentatie. Voor sales is het nog interessanter; zij kunnen in een handomdraai een nieuwe offerte genereren die gebaseerd is op de beste voorstellen en prijsafspraken uit het verleden. De AI combineert de specifieke klantvraag met bouwblokken uit jouw archief, inclusief de juiste voorwaarden en productspecificaties die je eerder hebt gebruikt. Dit soort toepassingen zorgen ervoor dat je team zich kan focussen op het menselijke klantcontact in plaats van op het administratieve typwerk.
Vanuit Onze Ervaring: Voor marketingteams is de specifieke ‘tone of voice’ vaak een struikelblok. Wij adviseren daarom altijd om concrete ‘stijlgids’-documenten toe te voegen aan de RAG-kennisbank. We zien dit direct terug in het resultaat: de gegenereerde teksten voelen authentieker en vragen minder redigeerwerk van uw copywriters.
Veelgemaakte fouten bij de implementatie van RAG (en hoe je ze vermijdt)
Een van de meest gemaakte fouten die we zien bij bedrijven die enthousiast aan de slag gaan, is het onderschatten van de kwaliteit van hun eigen bronmateriaal. In de technische wereld wordt hiervoor vaak garbage in, garbage out gehanteerd, en dat geldt dubbel zo hard voor moderne AI-toepassingen. Als je verouderde handleidingen, tegenstrijdige memo’s of slecht gescande documenten in je database stopt, zal de chatbot onherroepelijk verwarrende of foute antwoorden geven. Het systeem is namelijk geen wonderdokter die je administratieve chaos repareert; het is een harde spiegel die precies laat zien hoe goed (of slecht) je documentatie op orde is. Daarom besteden we bij een implementatie vaak de meeste tijd aan het opschonen en structureren van data voordat we überhaupt de eerste regel code schrijven. In onze projecten besteden we daarom vaak de eerste twee weken puur aan data-hygiëne, nog voordat we de AI-technologie inschakelen.

Daarnaast zien we projecten vaak stranden omdat er geen helder, meetbaar bedrijfsdoel is geformuleerd. Het is erg verleidelijk om een chatbot te bouwen “omdat het kan” of omdat je ergens hebt gelezen dat de concurrentie het ook doet, maar zonder focus levert het zelden waarde op. Je moet van tevoren precies definiëren welk pijnlijk probleem je wilt oplossen, zoals het halveren van de zoektijd voor supportmedewerkers of het versnellen van de onboarding van nieuwe collega’s. Zonder zo’n concrete doelstelling wordt het project al snel een leuke technische speeltuin zonder daadwerkelijk resultaat voor de organisatie. Een succesvolle implementatie begint simpelweg niet met technologie, maar met een scherpe vraag over waar je team nu eigenlijk de meeste tijd en energie verliest.
Een andere klassieke valkuil waar zelfs ervaren IT-teams nog weleens intuimelen, is het idee dat je alle soorten data blindelings in een RAG-systeem kunt gooien. Taalmodellen zijn fantastisch in het begrijpen van tekst, context en nuance, maar ze zijn historisch gezien onbetrouwbaar als het gaat om zwaar rekenwerk of harde statistieken. Als je de AI vraagt om het gemiddelde rapportcijfer of een exacte financiële KPI te berekenen op basis van twintig losse PDF-rapporten, is de kans groot dat hij er compleet naast zit. Voor harde cijfers en exacte berekeningen ben je nog steeds veel beter af met een traditionele database (SQL) of een goed ingerichte spreadsheet. Gebruik RAG waar het goed in is, namelijk het vinden van antwoorden in tekst, en laat het rekenwerk over aan systemen die daarvoor zijn gemaakt.
Tot slot wordt de technische complexiteit van een goed werkend systeem in productie vaak enorm onderschat door managers. Een simpele demo waarbij je met één PDF kunt chatten is in vijf minuten gebouwd, maar een robuust systeem dat dagelijks met live bedrijfsdata werkt vereist meer aandacht. Je hebt slimme koppelingen nodig die automatisch nieuwe bestanden verwerken en verouderde informatie direct verwijderen, iets wat we vaak automatiseren met tools zoals n8n. Zonder dit onderhoud veroudert je kennisbank snel en verliest het team zijn vertrouwen in de antwoorden van de assistent, wat zonde is van de investering. Het bouwen van zo’n betrouwbare pijplijn vraagt om specifieke expertise die verder gaat dan alleen een abonnementje nemen op een standaard AI-tool.
RAG is de pragmatische stap naar AI die écht voor je werkt
Het mag inmiddels duidelijk zijn dat de dagen van handmatig knippen en plakken in een generiek AI-venster geteld zijn. Door te kiezen voor een RAG-systeem bouw je een cruciale brug tussen de algemene taalvaardigheid van AI en de specifieke realiteit van jouw onderneming. Je creëert hiermee geen vervanger voor je medewerkers, maar geeft ze een krachtig hulpmiddel dat direct toegang heeft tot jaren aan opgebouwde bedrijfskennis. De technologie is er niet om interessant te doen, maar om de dagelijkse frustratie van het zoeken naar informatie definitief weg te nemen. Het resultaat is een betrouwbare assistent die jouw klanten en procedures echt begrijpt, zonder dat je bang hoeft te zijn voor verzonnen feiten.
Het is misschien een boude claim maar ik durf te stellen dat RAG voor negentig procent van de KMO’s de meest logische instap is in de wereld van geavanceerde AI. Het is een pragmatische en budgetvriendelijkere oplossing die een direct probleem aanpakt zonder de torenhoge kosten die komen kijken bij het trainen van eigen modellen. Bij Bonalogic merken we dat bedrijven vaak verbaasd zijn over hoeveel waarde ze al uit hun bestaande, rommelige data kunnen halen zodra deze slim ontsloten wordt. Het gaat er niet om wie de meest futuristische tools heeft; het gaat erom wie zijn administratieve processen het slimst weet in te richten. Deze nuchtere benadering scheidt de succesvolle toepassingen van de dure experimenten die in de lade belanden.
Expert Advies
Op basis van onze ervaringen met tientallen RAG-implementaties geven we je graag deze twee adviezen mee:
- Begin niet met de technologie, maar met de data. Zorg eerst dat uw basisdocumentatie op orde is voordat u gaat automatiseren. Als u net begint, focus dan op een intern proces met een laag risico en duidelijk omschreven documentatie, zoals een IT-faq. Dit bouwt het noodzakelijke vertrouwen op om het systeem later succesvol naar complexere processen uit te breiden.
- De stap naar een slimmer bedrijf begint niet met een grote cheque, maar met het identificeren van dat ene proces waar iedereen een hekel aan heeft. Kijk eens kritisch naar je team en vraag je af waar ze dagelijks kostbare minuten verliezen aan het opzoeken van steeds dezelfde antwoorden. Dat specifieke pijnpunt is de ideale kandidaat voor je eerste RAG-project, dat we met efficiënte workflow-tools verrassend snel kunnen opzetten. Ga het gesprek aan met een expert die snapt dat technologie in dienst moet staan van jouw rendement, niet andersom. Laten we samen kijken hoe we jouw data voor je kunnen laten werken, zodat jij je weer kunt focussen op het ondernemen zelf.
